La Bioacoustic Unit dispose d’une bibliothèque grandissante d’outils de reconnaissance automatique.
Ces modèles peuvent être utilisés pour analyser des ensembles de données acoustiques pour des espèces individuelles. Dans ce document, nous discutons brièvement de ce qu’est un algorithme de détection (ou reconnaisseur) automatique, son fonctionnement et ses applications. Vous pouvez trouver des reconnaisseurs gratuits ici. Vous pouvez trouver des reconnaisseurs gratuits ici. Ils ont tous été conçus à partir du logiciel Song Scope de Wildlife Acoustics.
FAQ
Les enregistreurs autonomes sont de plus en plus utilisés sur le terrain pour déterminer la présence, l’absence et l’abondance des espèces d’oiseaux. Contrairement aux êtres humains, ces enregistreurs peuvent être laissés sur le terrain pendant de longues périodes, ce qui permet de recueillir des données sur des échelles spatiotemporelles beaucoup plus grandes. Toutefois, cette approche a pour inconvénient d’exiger beaucoup de travail dans le traitement d’aussi vastes ensembles de données. La détection automatique des espèces est une solution innovante qui transfère à l’ordinateur la charge d’écouter de nombreuses heures d’enregistrements audio.
En termes simples, la reconnaissance automatique d’espèces (à partir de données acoustiques) est le processus d’entraînement d’un ordinateur pour reconnaître, détecter et évaluer la signature acoustique de la vocalisation d’une espèce cible Par exemple, un modèle informatique peut apprendre à reconnaître la vocalisation distinctive de la chouette rayée (Strix varia), qui ressemble à la phrase « who cooks for you », en anglais.
Ce modèle, qu’on désigne aussi par le terme « reconnaisseur », peut ensuite être appliqué à des ensembles de données pour détecter les signaux qui ressemblent au modèle entraîné. Tous les types de sons peuvent être modélisés dans des logiciels de reconnaissance automatique, depuis les gloussements et les gémissements d’une grenouille au tambourinage d’un pic.
Les reconnaisseurs optimisent le traitement des ensembles de données acoustiques.
Comme nous l’avons mentionné précédemment, l’automatisation du processus de détection des espèces permet de traiter plus efficacement les ensembles de données. Cela est particulièrement vrai pour les espèces rares ou peu communes, car l’effort nécessaire pour les identifier manuellement est considérable.
Les reconnaisseurs fournissent de nombreux types de données.
Les informations les plus élémentaires que l’on peut obtenir de la reconnaissance automatique sont les données liées à la présence, à l’absence ou à l’occurrence des espèces. Lorsqu’on associe la reconnaissance automatique à des estimations de détectabilité, il est aussi possible de modéliser le taux d’occupation des espèces. Des méthodes récentes explorent la possibilité d’utiliser des dispositifs d’enregistrement groupés pour localiser un oiseau individuel dans le temps et l’espace. À l’avenir, cela pourrait conduire à des estimations de la densité animale, surtout pour les oiseaux rares ou peu communs. Les systèmes de reconnaissance automatique des espèces peuvent également fournir des informations sur la phénologie des vocalisations, les taux d’appel et la variation intraspécifique des appels.
Il existe de nombreuses approches de reconnaissance automatique des espèces (résumées brièvement dans l’article de Knight et coll., 2017). La Bioacoustic Unit mise principalement sur deux approches pour concevoir des modèles de reconnaissance automatique : (i) les algorithmes d’apprentissage supervisé et (ii) les réseaux neuronaux. Nous discuterons de la première approche ci-dessous.
Par algorithme d’apprentissage supervisé, on entend que l’utilisateur ou l’utilisatrice surveille l’ordinateur pendant la phase d’entraînement, alors qu’il « apprend » à quoi ressemble la vocalisation d’une espèce donnée. Cela se fait généralement à l’aide d’un logiciel appelé Song Scope. En premier lieu, l’ordinateur est alimenté d’exemples de vocalisations d’une espèce sous la forme de commentaires. Lorsque des données d’entraînement de haute qualité sont disponibles, les reconnaisseurs peuvent distinguer les signaux des bruits ambiants avec une grande précision.
Au cours de la phase d’apprentissage, certains paramètres sont définis par l’utilisateur ou l’utilisatrice (p. ex., le nombre de syllabes, la gamme de fréquences autorisées). Ensuite, l’aspect « supervisé » de l’algorithme entre en jeu. En définissant ces paramètres à l’aide d’antécédents biologiques (p. ex., la vocalisation comporte généralement sept syllabes, les plages extrêmes d’une vocalisation de l’enregistrement sont mesurées), on guide l’ordinateur vers l’espace de paramètres à partir duquel il sondera des ensembles de données réels. Une fois que l’efficacité du reconnaisseur est jugée satisfaisante, les seuils de qualité et de score peuvent être définis pour optimiser les taux de faux positifs et de faux négatifs.
« Tous les modèles sont faux, mais certains sont utiles. » Cet adage scientifique classique s’applique aux reconnaisseurs. Les reconnaisseurs peuvent être d’une très grande précision, mais ils produisent toujours de faux positifs (l’algorithme associe une vocalisation à une espèce X alors qu’il s’agit plutôt de l’espèce Y) et de faux négatifs (l’algorithme n’identifie pas l’espèce X même si elle émet des vocalisations).
En présence d’une grande quantité de données acoustiques, les reconnaisseurs produisent un grand nombre de résultats. Il faut donc vérifier soi-même les vocalisations. Cela consiste en l’étape de validation. Il existe de nombreuses façons de valider des données et la quantité de données à valider dépend de votre question de recherche. Si vous vous intéressez principalement à la présence ou à l’absence d’une espèce dans les enregistrements d’une saison complète, l’effort de validation nécessaire est bien moindre que si vous voulez tenir compte de chaque chant émis par une espèce. La Bioacoustic Unit a publié quelques articles sur la façon de réduire la durée du processus de validation. **Using tools like species verification in WildTrax can save time and help to manage and share your data outputs as well.
Un élément clé de cet organigramme est la qualité des enregistrements utilisés pour concevoir le reconnaisseur. Lors de la création et de l’interprétation des reconnaisseurs, il y a des avantages et des inconvénients à n’utiliser que des extraits de haute qualité captés très près de l’espèce d’intérêt. Lorsqu’entraînés avec des extraits de haute qualité captés à proximité de l’espèce qui émet des vocalisations, les reconnaisseurs n’identifient pas seulement l’espèce, mais « estiment » également la distance de celle-ci par rapport aux dispositifs d’enregistrement. Ainsi, ils sont plus susceptibles d’identifier les espèces proches des enregistreurs autonomes et de passer outre celles qui sont plus éloignées. En misant sur des vocalisations plus éloignées de l’enregistreur autonome pour entraîner les reconnaisseurs, on peut améliorer (mais pas toujours) leur capacité à identifier des espèces dans un enregistrement, car ils ont appris à détecter les ratios signal/bruit plus faibles d’animaux plus éloignés. Nous préférons utiliser des reconnaisseurs entraînés à partir d’enregistrements de haute qualité à proximité des dispositifs d’enregistrement en raison des avantages statistiques que procure la connaissance de la distance. Les reconnaisseurs conçus à partir de vocalisations de différentes qualités et distances produisent souvent plus de faux positifs.
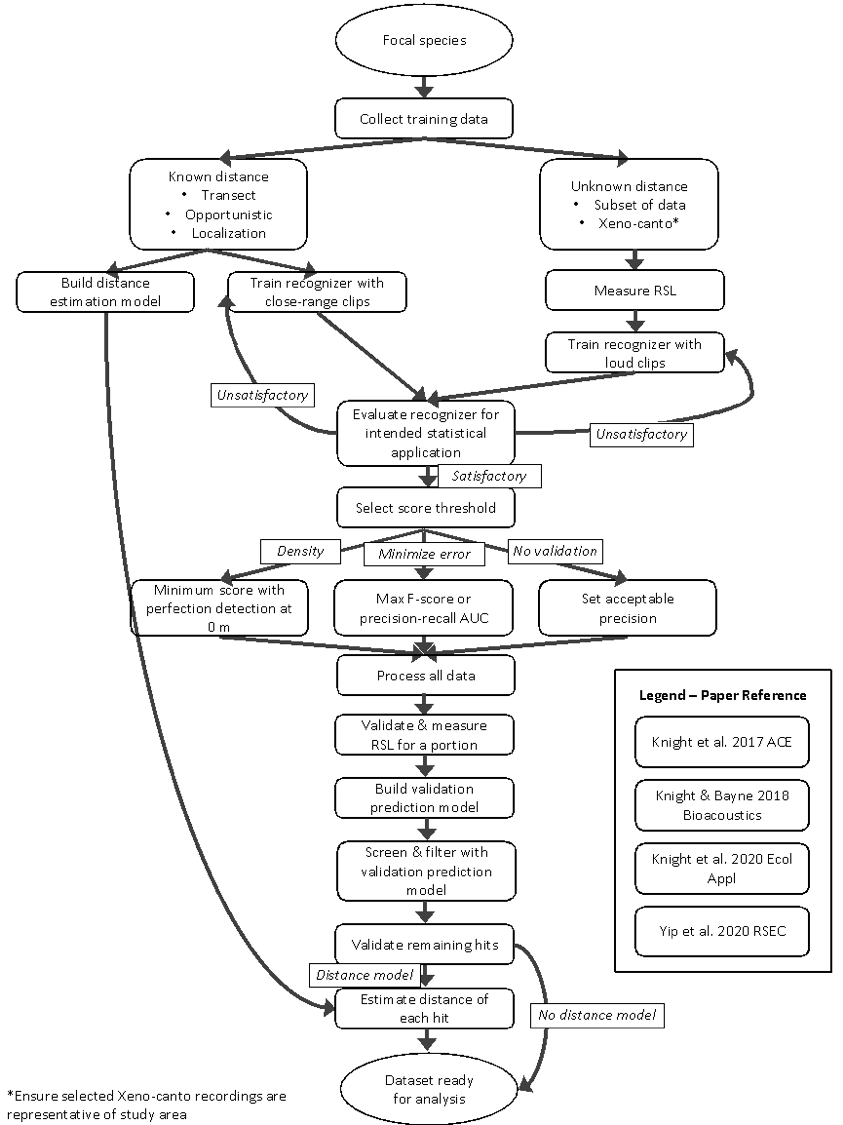
Tant que les résultats du reconnaisseur que vous avez généré contient les métadonnées appropriées, vous pouvez téléverser les médias, créer des tâches et téléverser les résultats comme étiquettes. Grâce à la vérification des espèces, vous pouvez ensuite vérifier rapidement les résultats. Consultez les chapitres du Guide sur les projets d’enregistreurs autonomes et la vérification des espèces pour en savoir plus.





















