The Bioacoustic Unit has a growing library of automated recognizers:
These are models that can be used to scan acoustic datasets for individual species. Here we briefly discuss what a recognizer is, how these models are made, and how they can be applied. You can find our freely available recognizers here. All were built in Wildlife Acoustics Songscope software.
FAQs
Biologists are increasingly using autonomous recording units (ARUs) in the field to determine the presence/absence and the abundance of bird species. Unlike humans, these recorders can be left in the field for extensive periods of time, allowing data to be collected over much greater spatiotemporal scales. However, the tradeoff in this approach is the labour-intensive nature of processing such vast datasets. Here, automated species detection provides a path forwards, by shifting the burden of sifting through hours of audio recordings from the technician to the computer.
Put simply, automated (acoustic) species recognition is the process of training a computer to recognize, detect, and evaluate the acoustic signature of a target species’ vocalization. For example, a computer model can be trained to recognize the distinctive “who-cooks-for-you” vocalization of a Barred owl (Strix varia).
Such a model, commonly referred to as a “recognizer”, can then be applied to acoustic datasets to detect signals that resemble the trained model. All types of sounds can be modeled into recognizers, from the chucks and whines of a frog to the drumming of a woodpecker.
Recognizers can make processing acoustic datasets more efficient
As mentioned above, by automating the species detection process, datasets can be processed more efficiently. This is especially true for rare or uncommon species because the amount of effort required to identify those species manually can be substantial.
Recognizers provide many different kinds of data
The most basic information that can be obtained from automated recognition is presence/absence or occurrence data. When coupled with estimates of detection probability, occupancy may also be modeled. Recent methods are exploring the possibility of using clustered recording units to localize an individual bird in time and space. In the future, this could lead to estimates of density, particularly for rare or uncommon birds. Automated species recognizers can also provide information on vocalization phenology, calling rates, and intra-specific variation in calls.
There are many approaches to automated acoustic species recognition (summarized briefly in Knight et al., 2017). Generally, the BU has implemented two major approaches to building recognizers: (i) supervised learning algorithms and (ii) neural networks. The former will be discussed below.
By supervised learning algorithm, we mean that the user monitors the computer during the training stage, where the computer is ‘learning’ what a particular species’ vocalization sounds like. This is typically done using a software called SongScope, which is first fed example annotations of a species’ vocalization, to train the computer on. Where high quality training data is available the recognizers can be very accurate in their ability to discriminate signal from the noise.
During the training stage, a number of parameters have their values informed by the user (e.g. number of syllables, range of permitted frequencies, etc.). This is where the ‘supervised’ part of the algorithm comes into play. By setting these parameters using biologically informed priors (e.g. we know that the vocalization usually has 7 syllables, or we can measure the extreme ranges picked up for that vocalization in recordings), the user helps guide the computer to the parameter space it will use to search through real datasets. After preliminary assessments of the recognizer model’s efficacy deem the model satisfactory, then the quality and score thresholds can be set to optimize false positive and negative rates.
“All models are wrong but some are useful”. This classic scientific adage applies to recognizers. While recognizers can be very accurate there will always be false positives (recognizer says that a vocalization is species X when it is really species Y) and false negatives (recognizers fails to find species X even though it was vocalizing).
With large amounts of acoustic data, the numbers of hits that the recognizer gets means you can’t be 100% sure that the computer is correct without checking the vocalization yourself. This is called validation or verification. There are many ways to validate data and how much you need to validate depends on your question. If you are primarily interested in whether a species is present or absent over an entire season of recordings the amount of validation needed is much less than if you want to count every song given by a species. The BU has a number of papers that discuss ways to reduce validation time that can be found here. Using tools like species verification in WildTrax can save time and help to manage and share your data outputs as well.
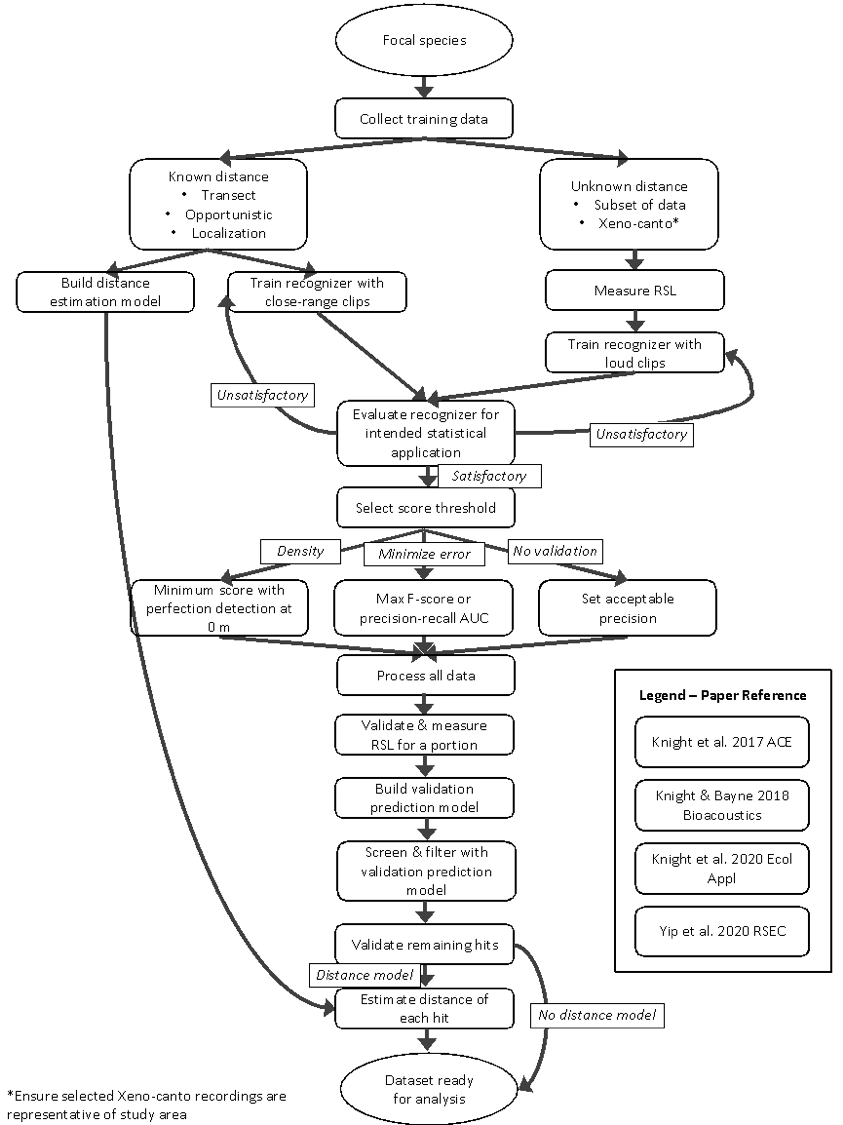
The flow chart below is the process the BU uses when developing and using recognizers and provides links to papers that provide more detail. A key element of this flowchart is the quality of recordings used to build a recognizer. There are trade-offs in the creation and interpretation of recognizers when you only use high-quality clips recorded very close to the species of interest versus using recordings of different qualities coming from species at different distances. When trained with high-quality close-clips a recognizer not only identifies the species but also “estimates” distance in that it will be more likely to find the vocalizations of species that are close to the ARU and miss those further away. Training the recognizer using vocalizations that are further from the ARU can improve (but not always) the ability to find a species in the recording because it is trained to detect weaker signal to noise ratios that come from more distant animals. We prefer to use recognizers built from high-quality recordings near the recording device because of the statistical benefits of knowing distance. Recognizers built using vocalizations of different quality and distances often have more false positives.
As long as the recognizer output you generated contains the appropriate metadata, you can upload the media, create tasks and upload the hits as tags. Using species verification, you can then quickly verify the hits. See the chapters of the Guide on ARU projects and Species verification to learn more.





















